
How We Picked the Right AI Model for Each Job
A Performance Tour of the A2B SmartRouter Catalog
aim2balance.ai Research Team
March 2026
Introduction: One App, Many Models
When you talk to aim2balance.ai, you see one chat box. Behind that single interface sits a catalog of large language models with very different strengths and costs. Some are specialists in coding, some excel at creative writing, some are strong at scientific reasoning, and some are multimodal agents that can read charts and files. No single system is the best at all of these tasks at once.
The A2B SmartRouter is the layer that decides which model to call for each request. Instead of forcing you to choose between obscure model names, we expose five intuitive routes: General Chat, Creative Writing, Logic & Science, Deep Engineering, and Agents & Tools. The router maps your prompt to one of these routes, then dispatches it to a model cocktail that has been empirically optimised for that capability.
In this article, we will analyze and profile all models in our catalog and take you through how we decided the best model cocktail behind each of the route that made up our AI system.
From Public Leaderboards to Route Rankings
The SmartRouter works with five semantically defined routes:
- General Chat for everyday questions, mixed-topic conversations, and safe, coherent dialogue.
- Creative Writing for stories, essays, marketing copy, and stylistic transformation.
- Logic & Science for math, STEM reasoning, academic explanations, and professional-domain questions.
- Deep Engineering for code generation, debugging, architecture, and technical specification work.
- Agents & Tools for tool orchestration, data and chart analysis, file understanding, and multimodal agentic tasks.
A separate evaluation for each route would be prohibitively expensive and environmentally wasteful. Instead, we reuse what the community has already produced: public benchmark leaderboards.
Harvesting and Normalising Existing Benchmarks
We collected 14 public leaderboards that jointly cover reasoning, coding, tool use, creative writing, and multilingual performance. Each leaderboard reports scores for overlapping sets of the 71 models in our catalog. The challenge is that they differ in three important ways:
- Different metrics: pass rates, judge scores, ELO ratings, and proprietary scales.
- Different naming conventions: the same model appears under different strings in different leaderboards.
- Different task scopes: some evaluate code, some evaluate conversation, some focus on specialised domains.
We address this in three steps:
- Name matching: every raw model name is matched to a canonical identifier in our catalog. We assign a match score in [0, 1] to express confidence and carry that score forward.
- Metric tagging: each benchmark metric is tagged with one or more capability labels such as cap:logical_reasoning, cap:code_generation or cap:creative_writing. Those tags are then mapped to one or more routes. For example, code-generation metrics feed Deep Engineering, while creative-writing metrics feed both Creative Writing and General Chat.
- Normalisation and weighting: scores within each metric are min–max normalised to [0, 1]. Each score is then multiplied by a smooth function of its name-match confidence so that well-matched entries contribute more and ambiguous entries contribute less
For each route, we aggregate all tagged, normalised, and confidence-weighted scores into a single strength number per model. We then run a pairwise ELO tournament over these strengths to createa stable ranking: models that repeatedly outperform others on route-relevant benchmarks rise to the top.
-
Key insight: We never limit ourselves to exact model matches. Each leaderboard contains variants of thesame family, and no single model appears everywhere. Our system dynamically aggregatesevidence from the closest available relatives to build the most complete capability profilepossible, using family-level performance as an honest proxy when exact matches are sparse.
Five Routes, Five Performance Profiles
In the figures below, each route has a radar chart summarising the capabilities that matter most for that route. Each axis is a capability dimension; the further a model reaches along an axis, the stronger its aggregated score there. We highlight the models that anchor our final cocktail.
General chat
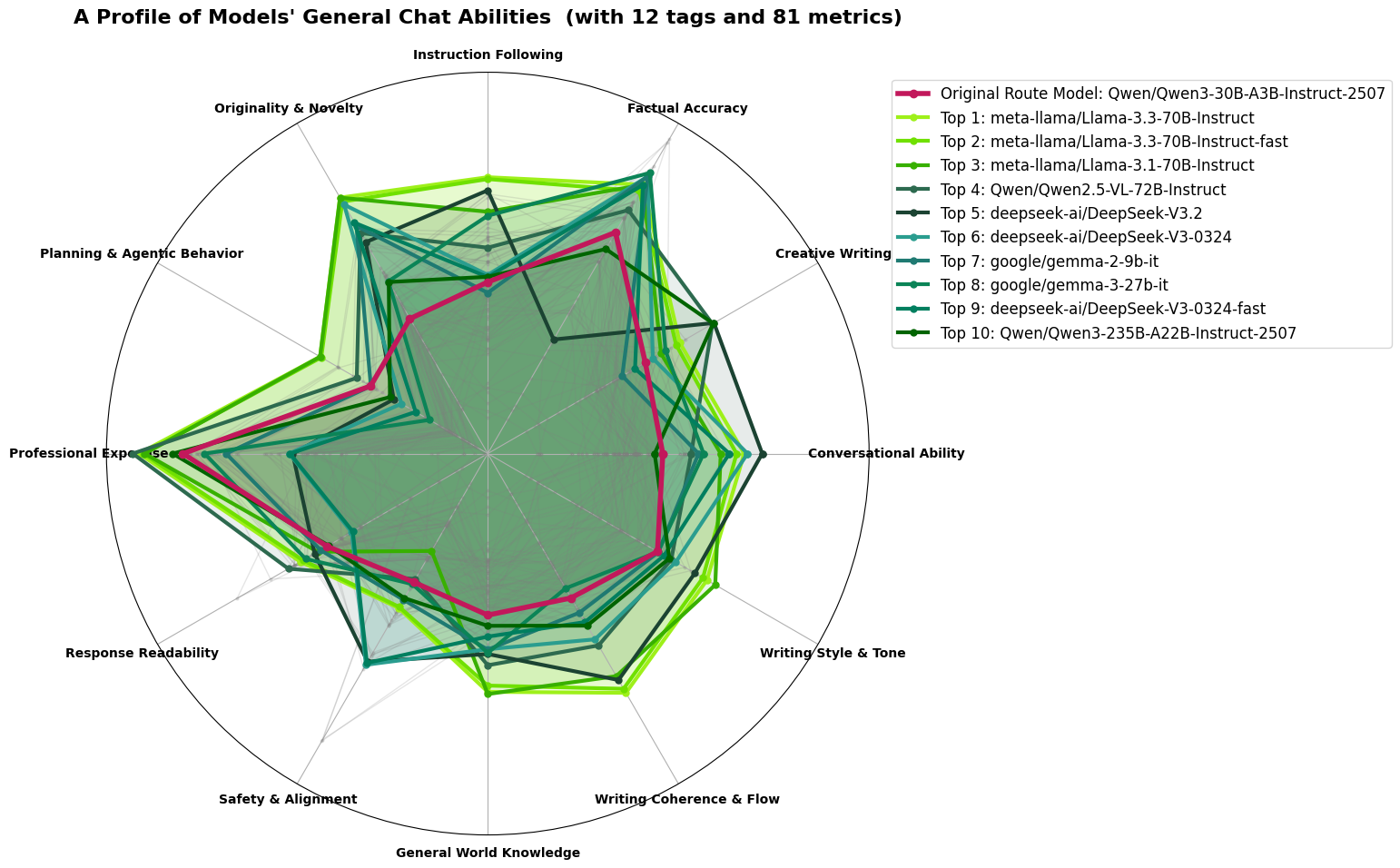
The General Chat route combines conversational fluency, factual accuracy, safety, instruction following, and basic writing quality. The radar in Figure 1 shows that Llama-3.3-70B-Instruct traces the largest and most balanced shape: strong on accuracy, strong on safety, strong on coherence, and no major weaknesses on any axis. Our previous backbone, a 30B Qwen model, covers the same space less completely and appears lower in the ELO ranking.
Selected primary model for General Chat: Llama-3.3-70B-Instruct.
Creative writing
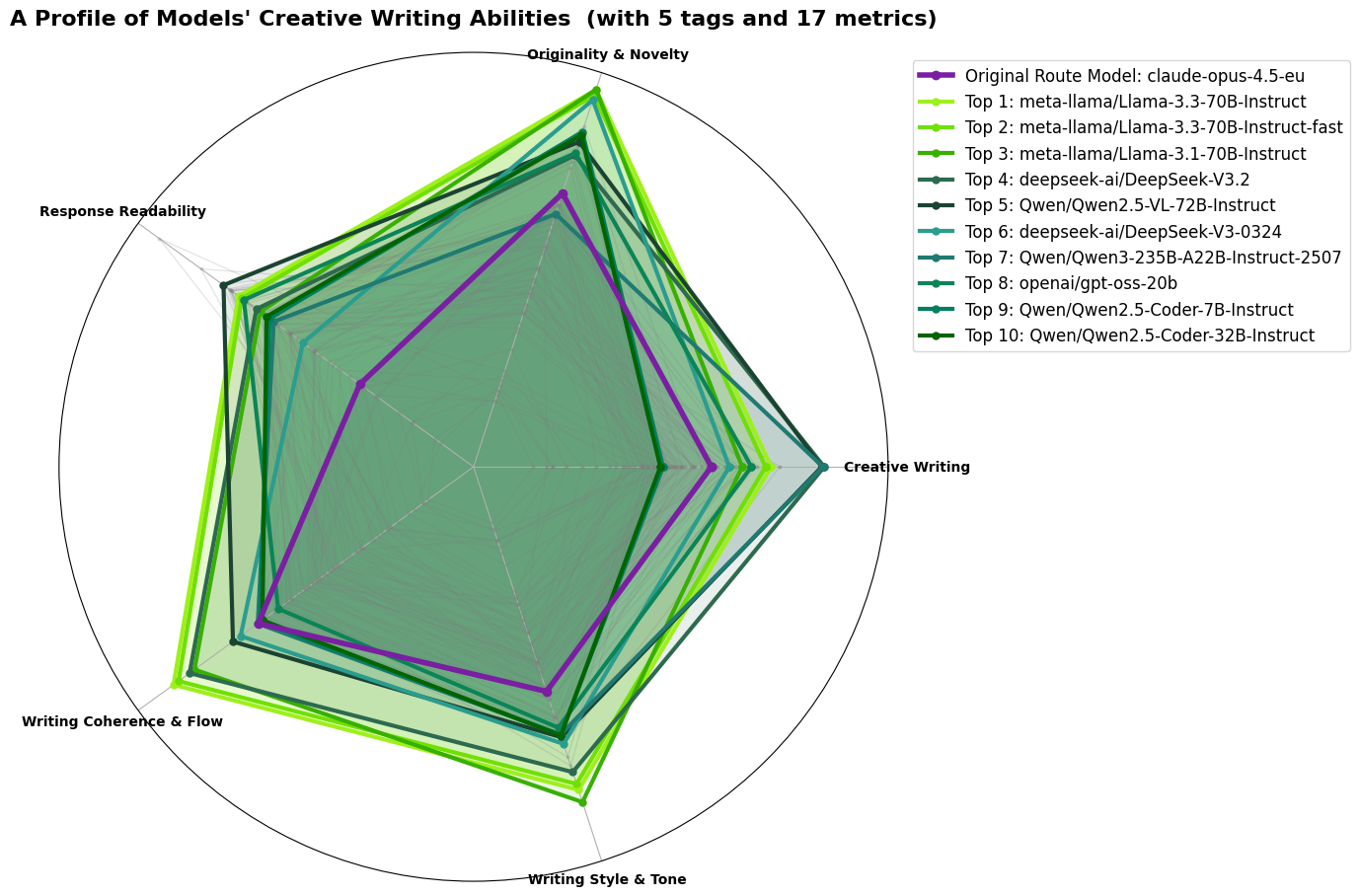
Creative Writing rewards originality, stylistic flexibility, and coherent long-form text. Figure 2 shows that the leaderboard is shared between Llama 70B models and a newer mixture-of-experts model, Qwen3-235B-A22B-Instruct-2507. This Qwen3 model activates 22 billion parameters per call while drawing on a larger pool of experts, giving it wide stylistic range at a cost closer to a mid-size dense model. Its originality and style axes are especially strong, while its coherence remains competitive with the Llama family.
Selected primary model for Creative Writing: Qwen3-235B-A22B-Instruct-2507.
Logic and Science
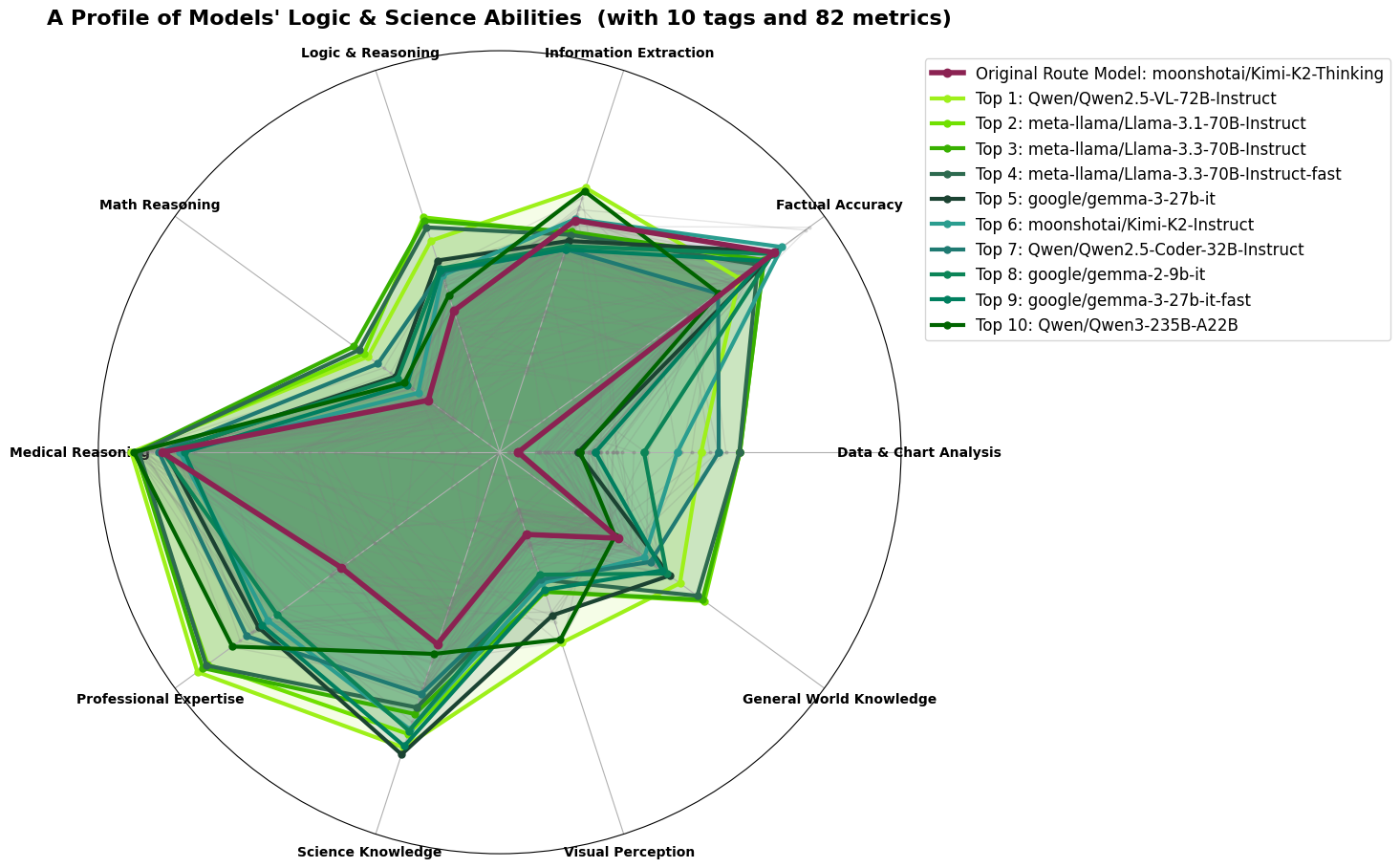
The Logic & Science route handles graduate-level math, STEM reasoning, medical questions, and professional-domain queries. The ELO leaderboard places Llama-3.1 and 3.3-70B at the top, but both are already committed to General Chat where their breadth and safety alignment are most valuable—deploying the same model across multiple routes defeats the purpose of a routing architecture. DeepSeek variants are competitive on pure reasoning axes, but their thin multilingual coverage makes them a poor fit for a European-first platform where queries in German, French, Czech, and Portuguese are routine, a limitation explored in detail in the next post.
That leaves Gemma-3-27B-it as the strongest available candidate: despite being the smallest model in the top five by parameter count, it shows exceptional depth on Medical Reasoning and Professional Expertise—the two axes most critical for this route—while remaining competitive on Science Knowledge and Math Reasoning.
Selected primary model for Logic & Science: Gemma-3-27B-it.
Deep Engineering: The Right Specialist for the Right Reasons
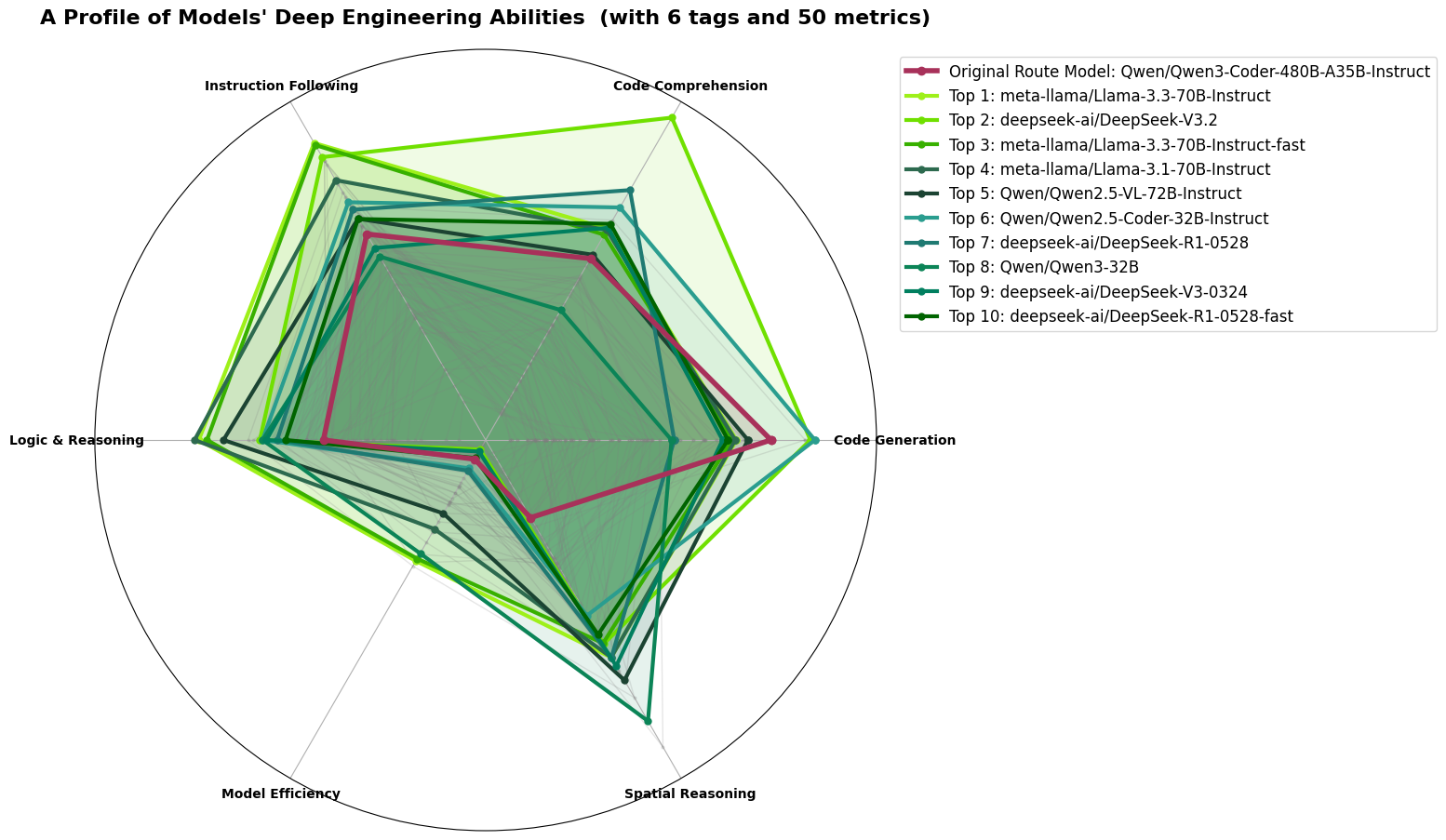
The Deep Engineering route serves developers and technical teams requiring precise code generation, debugging and system design across six axes: Code Generation, Code Comprehension, Instruction Following, Logic & Reasoning, Spatial Reasoning, and Model Efficiency. Llama-3.3-70B leads the ELO ranking but is already committed to General Chat; DeepSeek-V3.2 sits at rank 2 with a strong Code Generation spike but carries the same thin multilingual coverage that disqualified it from Logic & Science; and Qwen2.5-VL-72B, which ranks fifth with a well-balanced radar across all six axes, is reserved for Agents & Tools where its multimodal capabilities are irreplaceable.
That leaves the Qwen coding family as the natural candidate, and specifically Qwen3-Coder-30B-A3B-Instruct: a mixture-of-experts model activating only 3 billion parameters per inference step, whose capability profile is inferred in part from its well-evidenced Qwen2.5-Coder sibling and whose available benchmarks show Qwen2.5-Coder-level code quality, improved instruction following from the Qwen3 post-training cycle, and a Model Efficiency score no dense model in the top 10 approaches—making it the most cost-effective and capable available choice for production engineering workflows, with Qwen2.5-Coder-32B retained as a higher-capacity secondary for the heaviest tasks.
Selected primary model for Deep Engineering: Qwen3-Coder-30B-A3B-Instruct.
Agents & Tools
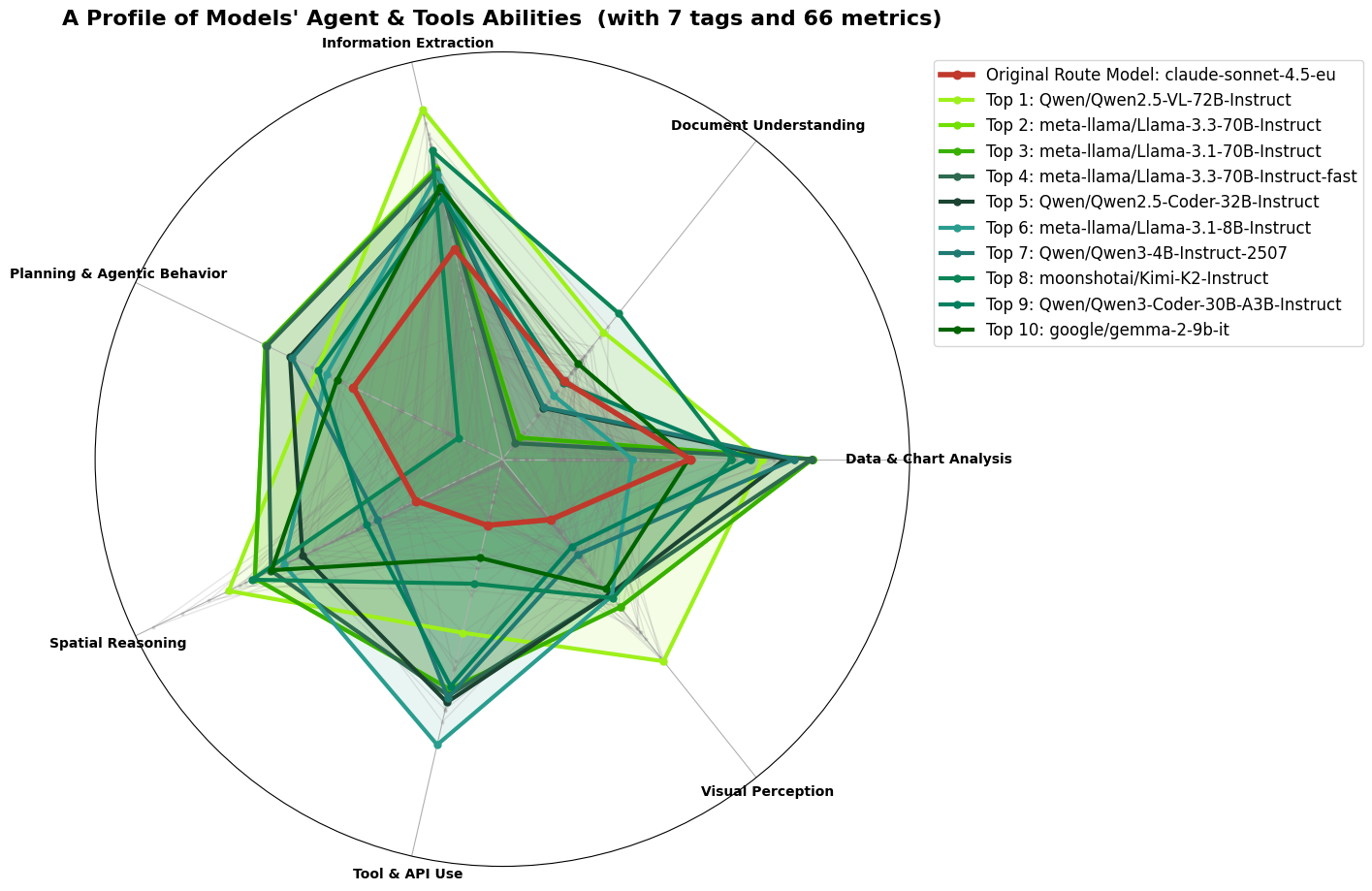
The Agents & Tools route demands versatility and precision, requiring models adept at handling complex tasks like multi-step tool execution, API parsing, and spatial reasoning. Qwen 2.5-VL-72B-Instruct excels in these areas, leading the rankings with its superior multimodal capabilities.
Agents & Tools is the most complex route. It requires models that can plan multi-step tool calls, parse API responses, read charts and tables, and reason about spatial layouts. The radar in Figure 5 shows Qwen 2.5-VL-72B-Instruct clearly ahead on the multimodal axes: data and chart analysis, visual perception, and document understanding.
This is reflected in the ELO scores. Qwen2.5-VL-72B leads the Agents & Tools ranking by a wide margin because it is the only model that combines strong text capabilities with competitive performance on multimodal and tool-use benchmarks.
Smaller models like Gemma-3-27B-it perform well on document understanding and information extraction but lack the same depth on visual tasks. Our previous route model, a Claude variant, appears much lower in this pipeline because public benchmarks have not fully caught up with its latest generation.
Selected primary model for Agents & Tools: Qwen2.5-VL-72B-Instruct.
The Final Model Cocktail
Taken together, these results show that there is no single best model. The same Llama model that dominates General Chat is not the most efficient coder. The model that leads engineering tasks is not the best at reading charts and files. The SmartRouter’s job is to turn this diversity into an advantage by pairing each incoming prompt with a route and each route with a well-justified model choice.
For everyday usage, this means that aim2balance.ai silently selects Llama-3.3-70B-Instruct for most general queries, Qwen3-235B for creative work, Gemma-3-27B-it for scientific questions, Qwen3-Coder-30B for engineering tasks, and Qwen2.5-VL-72B for agentic, tool-heavy workflows. Although you don’t explicitly see the router working its backend magic, rest assured you are getting the best models for every prompt you throw at our system!
Why Benchmarks Still Matter
Public benchmarks are not perfect. They are partial, noisy, and sometimes slow to include the very latest models. But when carefully normalised, tagged, and aggregated, they provide a concrete, inspectable basis for decisions that would otherwise be driven by hype, brand recognition, or anecdote.
Furthermore as new benchmarks appear and new models are released, we can recompute route rankings and update the cocktail without running a massive internal test suite from scratch. This keeps the SmartRouter aligned with the state of the art while staying within our environmental budget.