
Optimizing the aim2balance.ai SmartRouter
An inside look at the engineering and experiments behind aim2balance.ai’s intelligent routing system
“The future will be about combining different AI systems together.” — Yann LeCun
Imagine walking into a hospital where every patient, regardless of their complaint, is sent to the same neurosurgeon. A sprained ankle? Brain surgery. A sore throat?
It sounds absurd, yet this is precisely what happens when AI chatbots blindly route every user prompt to a single, monolithic large language model. The result is what you expect: wasted computational resources, unnecessary latency, and a one-size-fits-all approach that fails to honor the nuances of diverse inquiries and requests that are being asked of AI models.
At aim2balance.ai, we believe frontier AI capabilities should be accessible, cost-effective, and environmentally responsible for European users. The SmartRouter realizes this mission by reading the intent behind a question and directing it to the best-suited model in milliseconds. But this elegant simplicity hides a critical dependency on embedding geometry. This post chronicles our journey from hand-tuned intuition to data-driven optimization—revealing how our benchmark exposed surprising gaps between academic leaderboards and real-world performance, and why the words we choose to describe a task matter as much as the model interpreting them.
The Architecture of Intent
The SmartRouter operates within LibreChat, a unified interface that exposes diverse models from OpenAI, Anthropic, Google, and OpenRouter through a single API. Rather than asking users to manually select between models, a decision requiring expertise they may not possess, we handle the selection automatically by organizing the model catalog into five distinct routes:


When a user submits query s, it is encoded as vector q ∈ ℝᵈ and aligned against route utterances via cosine similarity. The best-matching route above threshold τ receives the request; otherwise, the system falls back to General Chat. The entire operation completes in under a millisecond—negligible against the seconds of model inference.
The Optimization Problem
Semantic routing trades the complexity of training a neural classifier for the simplicity of geometric comparison. But that simplicity is deceiving. We faced two interlocking questions that would determine whether the SmartRouter would be a precision instrument or a blunt instrument:
• Which embedding model should encode the vectors? Different models carve meaning-space into different shapes. Some create clean separation between technical and creative language; others collapse distinct domains into indistinguishable clusters. The choice of embedding model is effectively the choice of coordinate system for our semantic map.
• How should utterances be written? This is where craft meets science. The number of examples, their vocabulary level, and their syntactic complexity all influence how queries align with routes. A handful of well-crafted phrases might outperform fifty careless ones.
To answer these questions rigorously, we needed to move beyond intuition. We constructed a two-stage evaluation pipeline: first, profiling candidate embedding models using both standard multilingual benchmarks and a custom-built routing dataset; second, isolating the impact of utterance design through controlled sweeps across list length, sentence length, and vocabulary complexity.
When Leaderboards Lie
As it would turn out, academic benchmarks and real-world routing accuracy told contradictory stories (Figure 1).
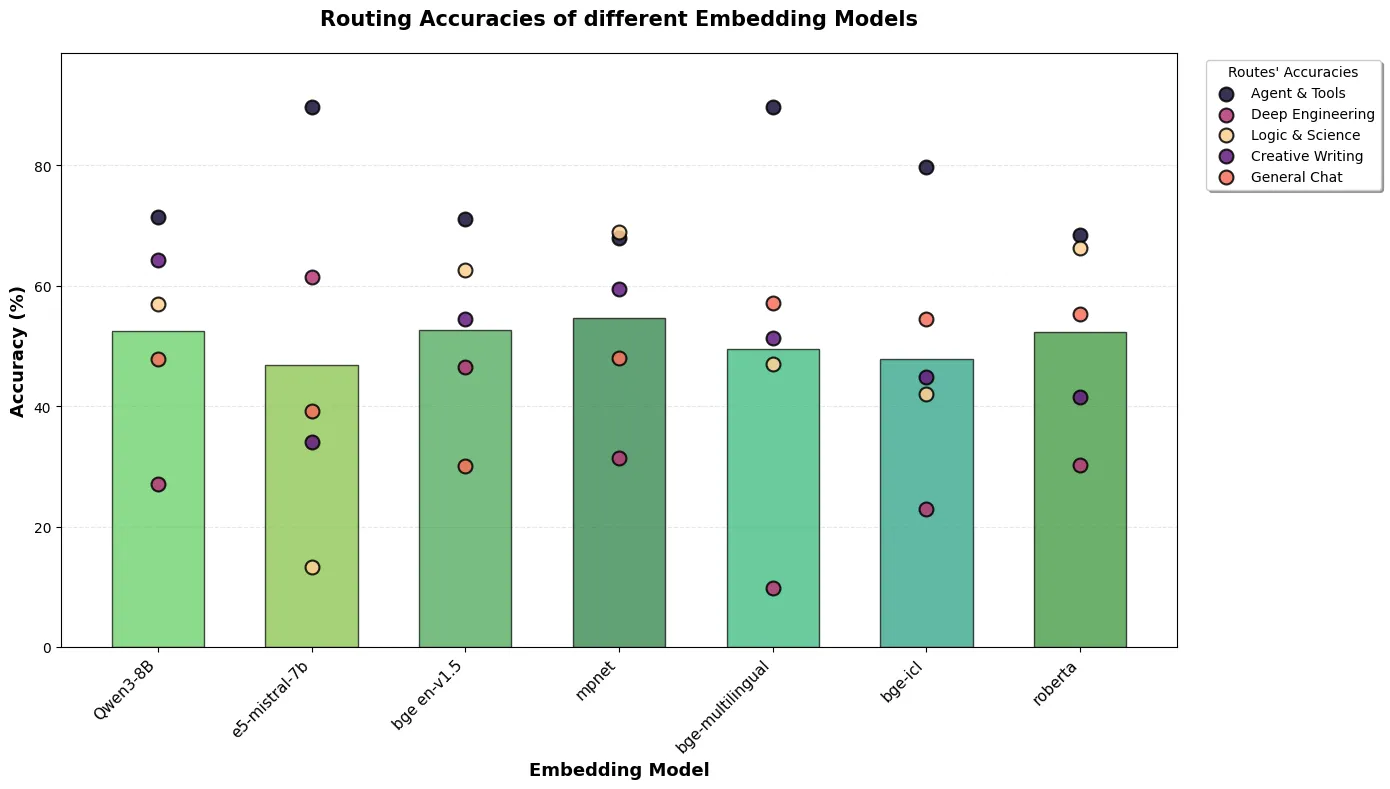
The compact all-mpnet-base-v2, a fast, lightweight model designed for dialogue similarity, delivered the highest average accuracy at approximately 58%. Close behind was Qwen3-Embedding-8B at 55%. Meanwhile, the BGE family, which dominates standard retrieval benchmarks and classification tasks, plummeted to 49–51% on our routing task. In contrast, Qwen3-Embedding-8B maintained a healthy 65% accuracy on Deep Engineering while preserving clean separation from Agents & Tools. Analysis of the cosine similarity distributions (Figure 2) reveals why. For four of five routes, correctly routed prompts cluster at similarities of 0.4–0.6, while incorrect routes cluster at 0.2–0.3, indicating strong intrinsic discriminability. Only General Chat inverted this pattern, showing lower similarities for correct assignments—a mathematical signature of its role as a fallback for prompts that fail to match any specialist route.
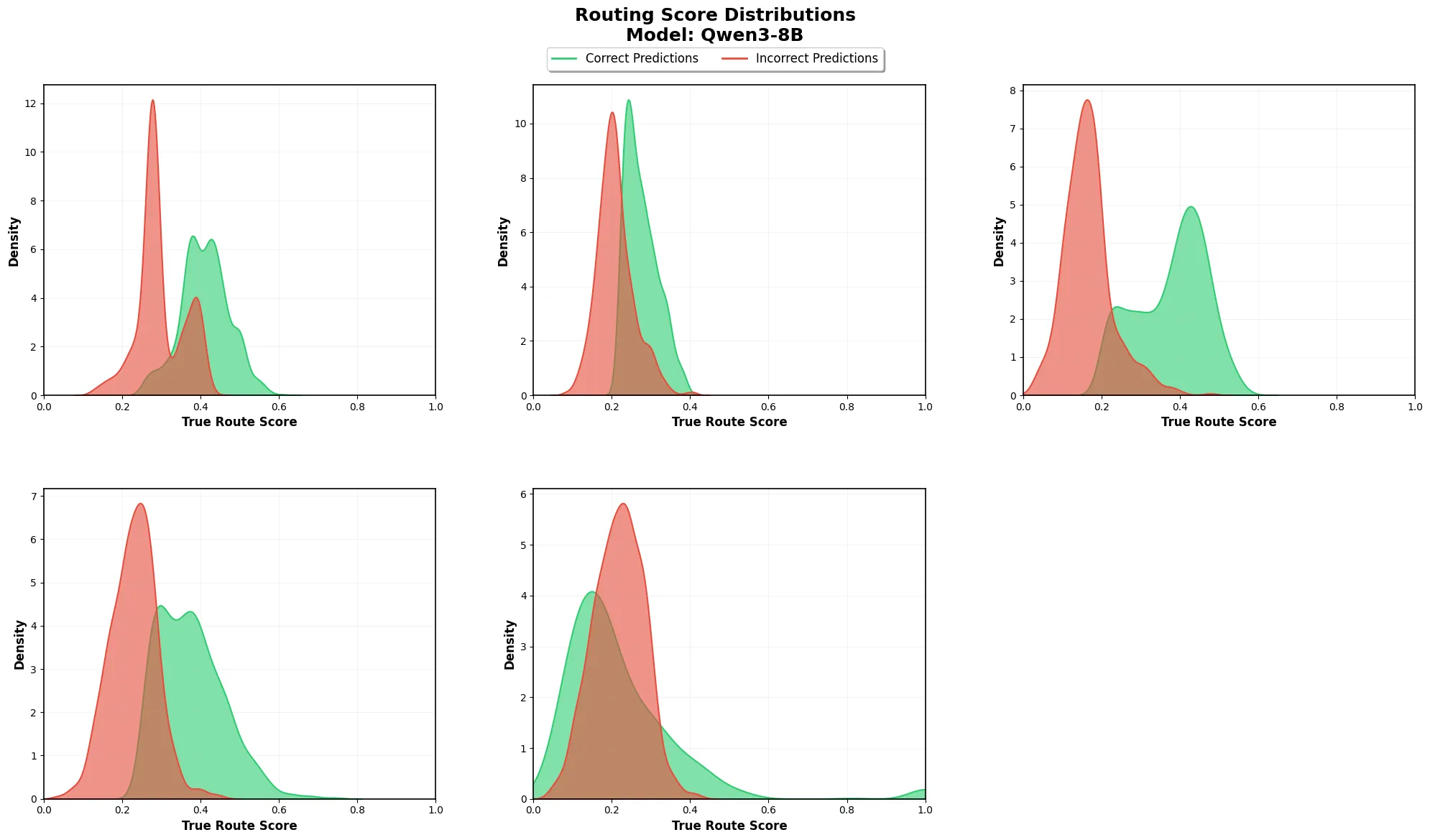
We selected Qwen3-Embedding-8B despite its slightly lower raw accuracy because it better serves our production needs: strong multilingual MMTEB scores eliminate the need for separate language-specific models, its 4096-dimensional space provides headroom for scaling to additional routes, andcrucially, it delivers the most stable performance distribution across all five categories –avoiding thecatastrophic blind spots that all-mpnet-base-v2 exhibited in edge cases.
The Alchemy of Utterance Design
With the embedding model fixed, we turned to the craft of utterance writing. Here, we discovered that different routes respond to design choices in markedly different ways, i.e what works for Creative Writing can actively harm General Chat. Figure 3 captures these dynamics across three dimensions.
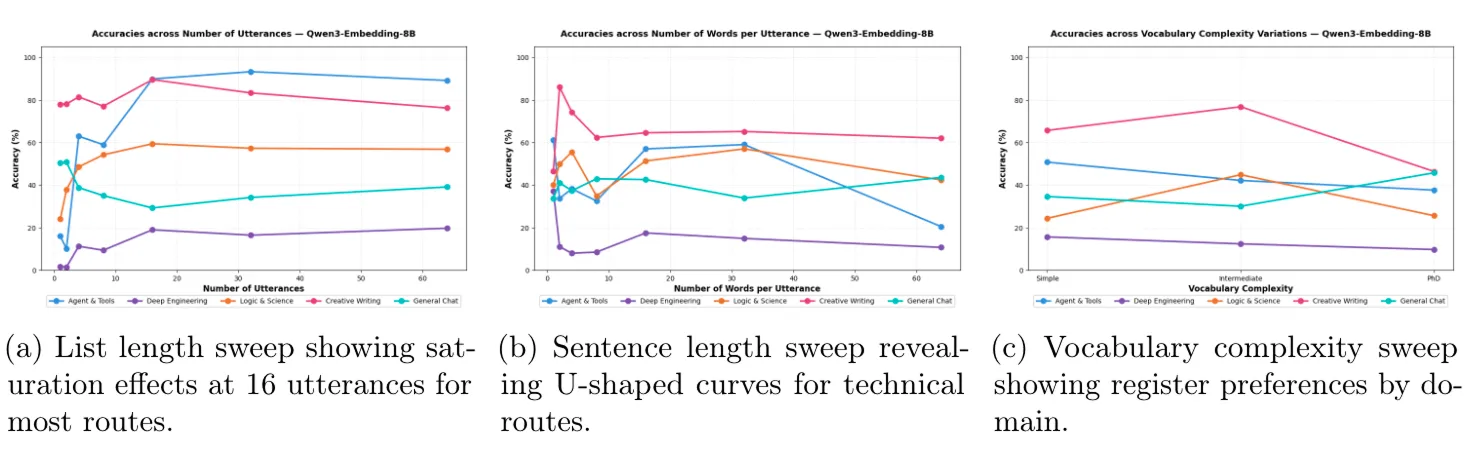
Our sweeps across the three dimensions revealed that different routes respond to utterance structure in markedly different ways (Figure 3).

Interestingly, General Chat exhibited an inverted pattern, peaking at 1–2 utterances and declining thereafter as generic phrases intruded into specialist territories, confirming the fallback route must remain deliberately minimal to avoid competing with defined categories. Sentence length revealed complementary U-shaped curves for Agents & Tools and Logic & Science, where moderate lengths of 15–32 words delivered optimal accuracy approaching 60%, while very short labels and verbose descriptions both underperformed (Figure 3b). Creative Writing peaked sharply at short lengths under 4 words, where compact phrases like “write tragic story” provide strong stylistic anchors.

These findings translate into a reproducible deployment configuration yielding roughly 28 percentage points improvement over single-utterance baselines. The optimized settings reveal clear patterns: specialist routes thrive on approximately 16 medium-length utterances with appropriate vocabulary, while Creative Writing peaks with fewer, shorter examples and General Chat functions best as a sparse, simple fallback. This pipeline regenerates configuration tables through transparent, human-auditable changes to utterance sets rather than opaque retraining, turning the growing heterogeneityof the LLM ecosystem into a practical, continuously improvable advantage.
 Read full article
Read full article